Il y a quelques jours de cela a eu lieu le workshop Intro to Data Analytics sur l’usage des données dans les web analytics. D’un niveau débutant, je me suis dit que ça serait serviable de vous rédiger un compte-rendu (sachant qu’il y aura d’autres sessions auxquelles vous pourrez participer).
La 1ère partie du workshop s’est focalisée sur des connaissances qu’il est nécessaire d’avoir dès le moment où l’on commence à faire des analyses (que l’on soit analyste ou pas) :
- Ce que l’on entend par données : de l’information disponible dans une variété de formats et tailles.
- En quoi consiste l’analyse de données : le processus d’examiner des données pour tirer des conclusions à partir de l’information.
- Ce que fait un analyste de données : interpréter les données pour générer des faits qui vont permettre la prise de décision.
- Quelques mots sur les outils : Excel, Tableau, SQL, etc…
La 2ème partie du workshop était celle qui m’intriguait le plus vu qu’il était question d’un long exercice à travers lequel chaque participant allait devoir mettre en application la méthodologie suivante :
- Hypothèse : le challenge auquel je dois faire face.
- Préparation : extraire, transformer, charger – Vérifier la validité et la véracité des données.
- Analyse : le coeur de l’exercice
- Communication : comment partager nos conclusions
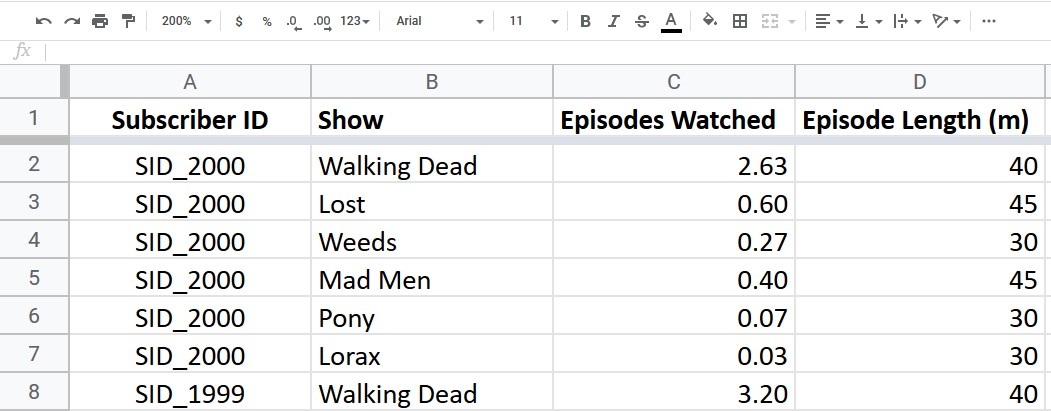
L’exercice consistait à travailler sur un ensemble de données capturées par Netflix lorsque les utilisateurs visionnent des émissions.

Sans nécessairement revenir en détails sur chaque étape (comme dit plus haut, vous pouvez participer à l’un des prochains événement), le formateur a souhaité démarrer par nous faire faire les 2 choses suivantes :
- Raconter l’histoire de ces données en 1 phrase : ça paraît évident, mais prendre le temps de résumer ce que ces données sont en 1 ligne va vous aider pour la suite et permet de clarifier ce à quoi on a affaire. Ci-dessus, on pourrait avoir quelque chose du type : « Durée et épisodes regardés par les utilisateurs Netflix ».
- Normaliser les données : vous ne le voyez pas dans la capture ci-dessus car j’avais déjà nettoyé le tableau mais normaliser les données présentées permet aussi de se retrouver avec un ensemble d’information plus propre dès le départ.
Durant l’analyse, le formateur a voulu familiariser les participants avec la création et l’usage des tables pivots dans Google Spreadsheet. Ce fut l’occasion de regrouper les données pour connaître le temps moyen passé par utilisateur sur chaque show, le nombre de minutes minimum pour chaque show et le maximum.

A partir de là, il a commencé à pousser les participants à analyser ces informations et à partager les idées de conclusion à en tirer. Ce fut aussi l’occasion de se requestionner sur les données afin de comprendre pourquoi nous avions beaucoup de show à 0 minute en temps minimum.
Par exemple, plutôt que d’avoir une conclusion du type « Walking Dead est le show le plus populaire auprès des usagers », il était plus intéressant d’arriver avec une approche « Le nombre de minutes minimum passées sur Walking Dead est X fois plus que le temps maximum passé sur Lorax, Mad Men, Pony ou Weeds« .
Enfin, il est revenu sur les différents types de statistiques à connaître : descriptives, inférentielles et prédictives (l’exercice illustrait ce dernier type).

Arnaud Mangasaryan est SEO manager chez Workleap et auteur / partageur d’expérience sur Histoire de Data.